
This is part 3 of the saga of the Adaptec Raid Controller – ASR-5405 that suddenly decided that my array was no longer there. Due to a motherboard bug on the Gigabyte motherboard of my test machine, four of my 1TB disk drives in the array was somehow configured to be 32MB in size. While researching the problem, I came across this great website that had a utility to fix the problem.
The utility they provide is to restore the hard disk drive factory capacity. It only runs on Windows – which isn’t a problem as such, and eventually I did this, and was able to turn each of my 1TB drives back into a 1TB drive – does that make sense? Or rather, turn my 32MB drives back into the original 1TB drives – yes, much more like it.
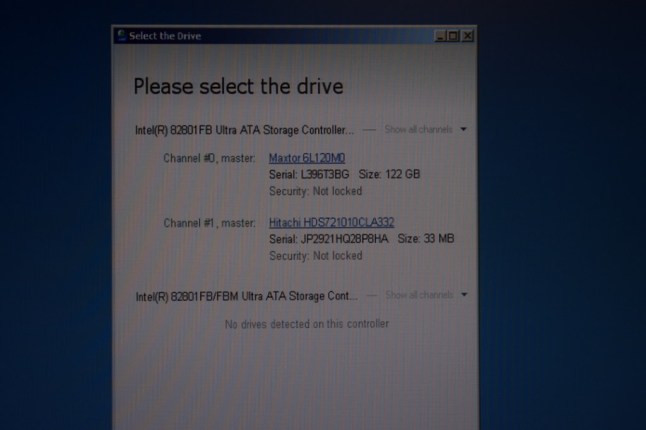
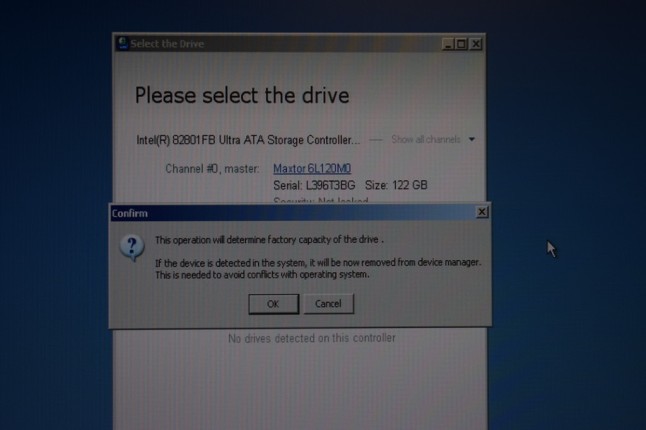
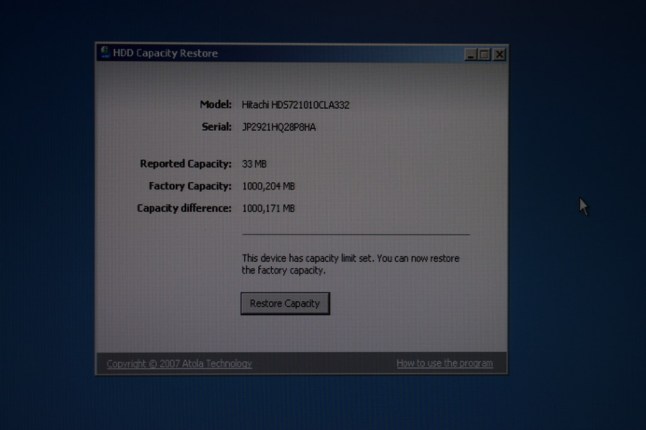
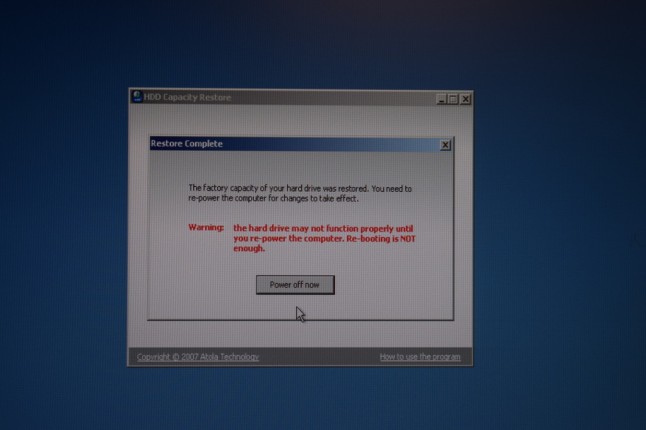
Now, I tried the drives back in the machine, however the Adaptec controller still insists that there is no logical drives found, even though it sees all four 1TB drives – including the one that was failing – I thought I should put that back in. The data isn’t really lost, since it is still sitting on three of the drives that are working. A RAID-5 array can tolerate one disk failure, so I have 3 out of 4 working drives from the array. All I have to do is to determine some parameters about the disk array. Sounds simple?
Most RAID-5 arrays use a distribute parity block, so effectively, we put data blocks on three disks with one disk having a parity block. Then the next three blocks go onto three disks, with a parity block on the other disk, except that it doesn’t go onto the disk that had the last parity block – not sure if I am explaining it properly. Anyway, what I have to do is to determine the block size, then the order of the data disks, and determine where the parity block goes first, then where the parity block goes next, and so on.
Once I work that out, then I can explain the layout a bit better. You will find terms like stripe factor, blocking factor, parity rotation order etc. What it means is that the parity block moves around the disks in a particular order. Last time, I had copied 10MB from each disk into files that I called arraydisk1, arraydisk2, arraydisk3 and arraydisk4. The number refers to the physical connection order on the array controller.
After some examination of the arraydisk files using a hex editor (which in this case is HexEdit), I was able to find some regular data structures in the files that allowed me to work out the size of the block – which was 256KB. Once I know the block size, I can then look at data just before and after the boundary and try to match it up. It is like a jigsaw puzzle – except we are working with data instead of shapes, but same sort of thing.
Last night, I was able to work out to my own satisfaction, that the physical disk order and the data disk order was the same, and that the parity block order was left asymmetric – which is nice and easy to explain. I also found some documentation on the internet that also indicated that Adaptec uses the left asymmetric parity block order.
My logical disk drive is 3TB, so just consider the following. The Adaptec controller writes the first 256KB onto the first disk, then the next 256KB onto the second disk, then another 256KB onto the third disk. A parity block which is comprised of the XOR of the previously written 256KB blocks – the result is written to the fourth disk. So now, we have 256KB of data or parity written to each disk. Now, the left asymmetric method says that the next parity disk will be the third disk. So now the next lot of data after what has already been written will be 256KB to the first disk, 256KB to the second disk, 256KB to the fourth disk and then the parity block generated will be written to the third disk. And so on, the next parity disk is the second disk, after that it is will be the first disk, then back to the fourth.
Got that? Ok, next to do will be to reverse this, since I have the first three disks, I can write my data to a new 3TB disk drive. I have a perl program that I wrote many years ago, just to do this – I just have to tailor it to just this situation. So, how do I do this?
Just imagine that this is what will happen, I will read 256KB from each disk 1, 2 & 3 – the first block of the disks comprise of data, so this will be written to the destination disk. The next 256KB blocks from the disks will be data, data, and parity – so the data blocks are written, then I do an XOR of the data blocks and parity block, and the result will be a data block that I write. So far, I have written six blocks, ok?
The next block from each disk will be data, parity, data – so again, write the data blocks, then XOR everything together, and write that as data – now I have nine blocks. The next block from each disk will be parity, data, data – so now I write the data blocks first, then XOR the blocks to get the new data block that is written to the disk. I now have written twelve blocks. The next block from each disk will be data, data, data – so we are the same as we were at the beginning of the disk – we just write out the data – and continue, ok?
So we keep going and eventually we have read the entire three disks and written 3TB or so of data – which I should be able to connect up and the computer should recognize the drive. Well, that is for another day to do, or maybe on the weekend. Wasn’t I lucky that it was the last disk that failed? Actually it really doesn’t matter which disk has failed, as long as we can determine the order of the drives.
As an example, what if it was the second disk that failed, and we have the first, third and fourth disk available. Since we know which is the parity block, we would know that the first block from each disk is data, data and parity – so as the missing disk is the second disk, we have to write data, XOR, and data – where XOR is the result of XOR on the two data blocks and the parity block. The next block we read would be data, parity, data, so we would write data, XOR, data. The third block, we would be reading data, data, data, so that is what we write as the block from the missing second disk would be parity, which we don’t need. Makes sense? Ok, I am glad it makes sense to someone. See you next time.
